Hengshi Documentation
Table of Contents generated with DocToc
Acceleration Engine
HENGSHI SENSE is equipped with a high-speed MPP engine that enables ad-hoc analysis of billion-level data and also allows the integration and modeling of heterogeneous data before performing associative computations.
Enabling the acceleration engine for a dataset will import the dataset's data into the engine, and queries for that dataset will directly access the engine tables.
Enabling the acceleration engine for different datasets will import them into the data warehouse separately, even if the datasets use the same tables multiple copies will be imported. Different datasets have different use cases, and users process these datasets in various ways, so once datasets are imported into the engine, they become isolated.
Enabling the Acceleration Engine
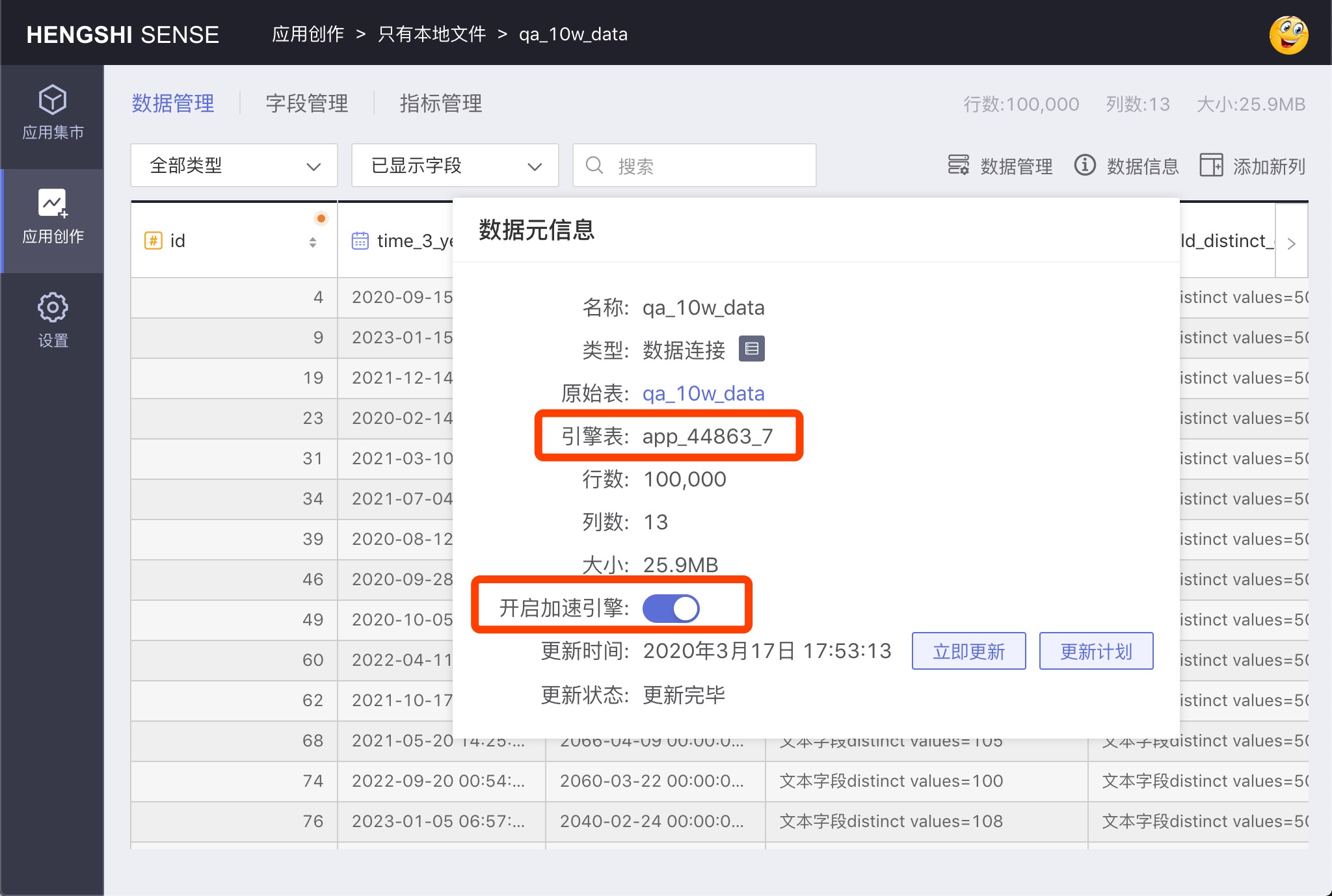
Click on the Data Source Information menu, and the Data Metadata Information window pops up. Turn on Enable Acceleration Engine, and the system will prompt "Please wait, data extraction in progress…". At this point, the system will extract the dataset into the engine.
After completion, the Engine Table name will be displayed in the metadata, as shown in the figure:
Disabling the Acceleration Engine
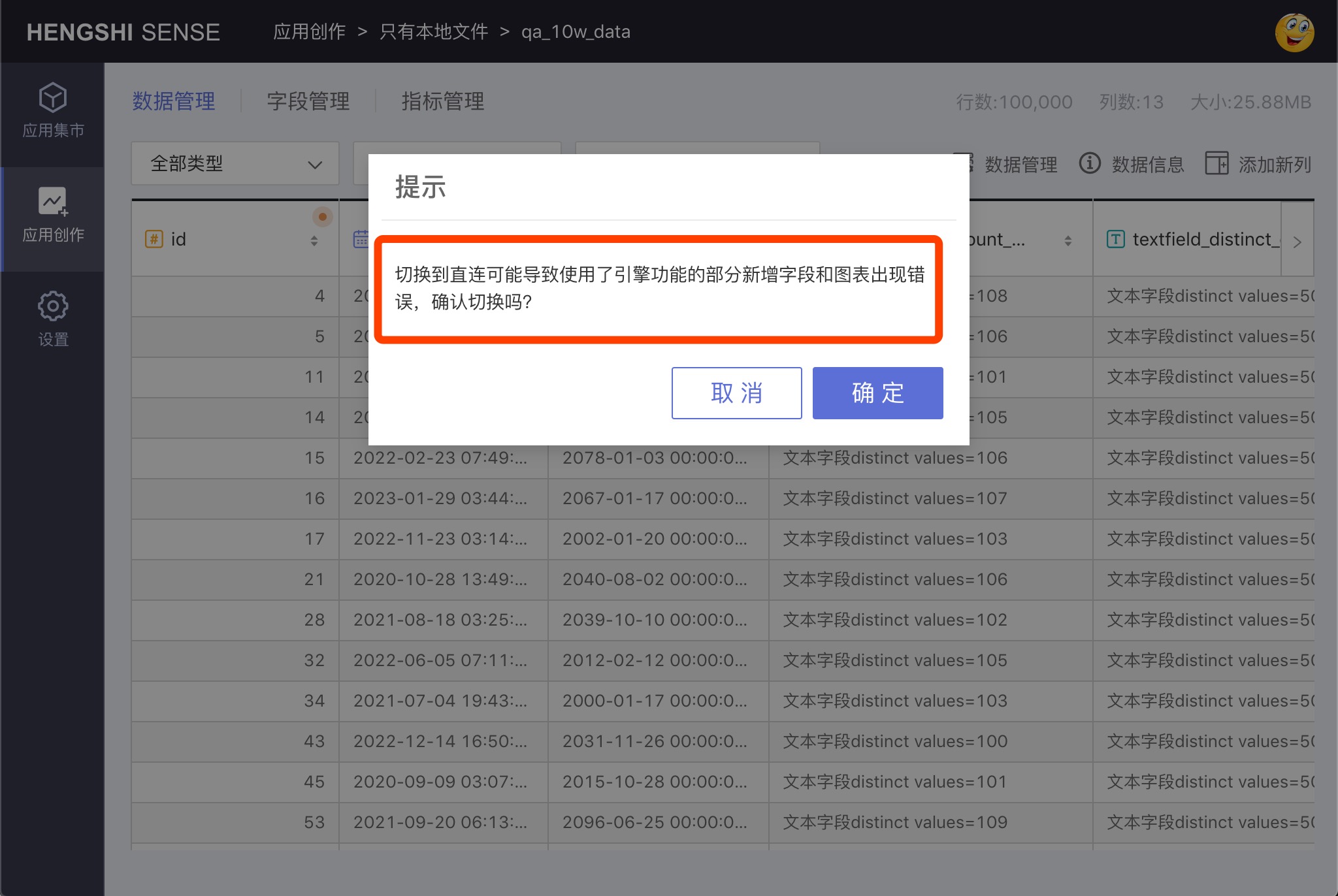
In the Data Metadata Information window, turn off Enable Acceleration Engine. After disabling the acceleration engine, the dataset will revert to direct connection to the original table mode. At this time, if new fields have used engine-supported functions that the original database does not support, the dataset will fail to load. If a new metric used functions supported by the engine but not by the original data, any visualizations using that metric will be in error. Therefore, the system will pop up a confirmation window, as shown below. Click confirm to disable the acceleration engine:
If the application has been published, the acceleration engine cannot be disabled.
Update Plan
In Update Plan, you can set the synchronization frequency between the engine tables and the original tables of the dataset.
For more information, see Update Plan.
Features Supported Only After Enabling the Acceleration Engine
- Appending Datasets
- Merging Datasets
- Multi-table Joins with Non-co-located Datasets
- Advanced Calculations: Mysql version 5 and below, as well as Tidb do not support window functions, so advanced calculations are not supported without importing them into the engine.
- Some Functions Not Supported by Direct-Connected Datasets: The engine supports all functions listed in the engine support documentation. Functions not supported by other data sources need to be imported into the engine to be supported.
Data Sources Not Supporting the Acceleration Engine
Currently, data sources that do not support enabling the acceleration engine include: Presto, Cloudera Impala, and Spark Sql.
These data sources are analysis engines in big data environments with their own analytical capabilities, and it is not necessary to import them into another analysis engine.
Hive is supported because it is not an MPP analysis engine itself. However, we do not recommend enabling the acceleration engine for Hive, as the data volume is too large, and importing it into a data warehouse is not suitable.